 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicies of Multiple Skill Levels for Better Strength Estimation in Games
May 01, 2025



Accurately estimating human skill levels is crucial for designing effective human-AI interactions so that AI can provide appropriate challenges or guidance. In games where AI players have beaten top human professionals, strength estimation plays a key role in adapting AI behavior to match human skill levels. In a previous state-of-the-art study, researchers have proposed a strength estimator trained using human players' match data. Given some matches, the strength estimator computes strength scores and uses them to estimate player ranks (skill levels). In this paper, we focus on the observation that human players' behavior tendency varies according to their strength and aim to improve the accuracy of strength estimation by taking this into account. Specifically, in addition to strength scores, we obtain policies for different skill levels from neural networks trained using human players' match data. We then combine features based on these policies with the strength scores to estimate strength. We conducted experiments on Go and chess. For Go, our method achieved an accuracy of 80% in strength estimation when given 10 matches, which increased to 92% when given 20 matches. In comparison, the previous state-of-the-art method had an accuracy of 71% with 10 matches and 84% with 20 matches, demonstrating improvements of 8-9%. We observed similar improvements in chess. These results contribute to developing a more accurate strength estimation method and to improving human-AI interaction.
Polygames: Improved Zero Learning
Jan 27, 2020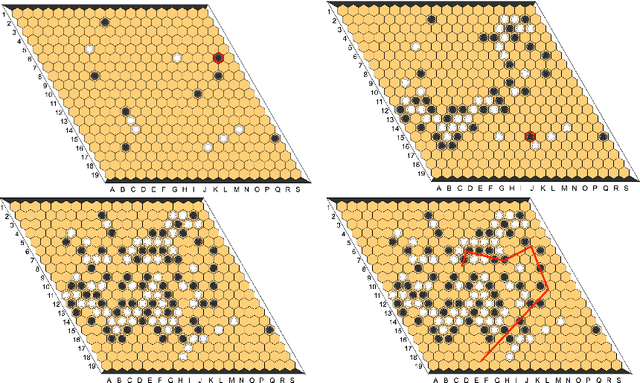
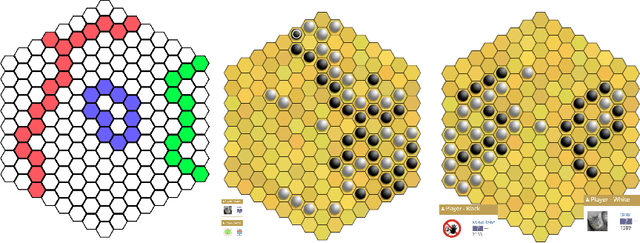
Since DeepMind's AlphaZero, Zero learning quickly became the state-of-the-art method for many board games. It can be improved using a fully convolutional structure (no fully connected layer). Using such an architecture plus global pooling, we can create bots independent of the board size. The training can be made more robust by keeping track of the best checkpoints during the training and by training against them. Using these features, we release Polygames, our framework for Zero learning, with its library of games and its checkpoints. We won against strong humans at the game of Hex in 19x19, which was often said to be untractable for zero learning; and in Havannah. We also won several first places at the TAAI competitions.
Human vs. Computer Go: Review and Prospect
Jun 07, 2016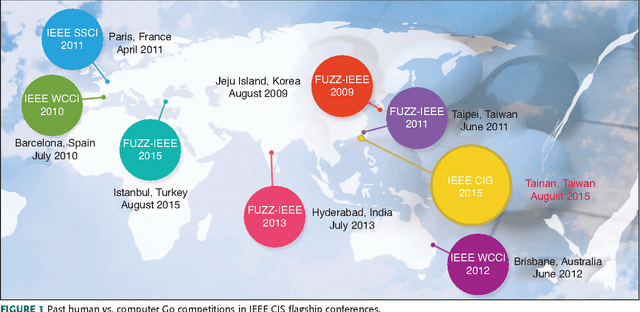
The Google DeepMind challenge match in March 2016 was a historic achievement for computer Go development. This article discusses the development of computational intelligence (CI) and its relative strength in comparison with human intelligence for the game of Go. We first summarize the milestones achieved for computer Go from 1998 to 2016. Then, the computer Go programs that have participated in previous IEEE CIS competitions as well as methods and techniques used in AlphaGo are briefly introduced. Commentaries from three high-level professional Go players on the five AlphaGo versus Lee Sedol games are also included. We conclude that AlphaGo beating Lee Sedol is a huge achievement in artificial intelligence (AI) based largely on CI methods. In the future, powerful computer Go programs such as AlphaGo are expected to be instrumental in promoting Go education and AI real-world applications.